User Guide
Note
“In our opinion, the main fact, which should be known to any person dealing with optimization models, is that in general, optimization problems are unsolvable. This statement, which is usually missing in standard optimization courses, is very important for understanding optimization theory and the logic of its development in the past and in the future.” — From Prof. Yurii Nesterov (International Member of National Academy of Sciences)
Before applying this open-source Python library PyPop7 (hosted in PyPI) to real-world black-box optimization (BBO) problems, four basic information should be read sequentially, as presented in the following:
Problem Definition
First, an objective function (also called fitness function in evolutionary computation or loss function in machine learning) needs to be defined in the function form. Then, data structure dict is used as a simple yet effective way to store all settings related to the optimization problem at hand, such as:
fitness_function: objective/cost function to be minimized (func),
ndim_problem: number of dimensionality (int),
upper_boundary: upper boundary of the search range (array_like),
lower_boundary: lower boundary of the search range (array_like).
Without loss of generality, only the minimization process is considered in this library, since maximization can be easily transferred to minimization by simply negating its objective function.
Below is a toy example to define the well-known test function called Rosenbrock from the optimization community:
1>>> import numpy as np # engine for numerical computing 2>>> def rosenbrock(x): # to define the fitness function to be minimized 3... return 100.0*np.sum(np.square(x[1:] - np.square(x[:-1]))) + np.sum(np.square(x[:-1] - 1.0)) 4>>> ndim_problem = 1000 # to define its settings 5>>> problem = {'fitness_function': rosenbrock, # cost function to be minimized 6... 'ndim_problem': ndim_problem, # dimension of cost function 7... 'lower_boundary': -10.0*np.ones((ndim_problem,)), # lower search boundary 8... 'upper_boundary': 10.0*np.ones((ndim_problem,))} # upper search boundary
When the fitness function itself involves other input arguments except the sampling point x (here we distinguish input arguments and above problem settings), there are two simple ways to support this more complex scenario:
1) to create a class wrapper, e.g.:
1>>> import numpy as np # engine for numerical computing 2>>> def rosenbrock(x, arg): # to define the fitness function to be minimized 3... return arg*np.sum(np.square(x[1:] - np.square(x[:-1]))) + np.sum(np.square(x[:-1] - 1.0)) 4>>> class Rosenbrock(object): # to build a class wrapper 5... def __init__(self, arg): # arg is an extra input argument 6... self.arg = arg 7... def __call__(self, x): # for fitness evaluations 8... return rosenbrock(x, self.arg) 9>>> ndim_problem = 1000 # to define its settings 10>>> problem = {'fitness_function': Rosenbrock(100.0), # cost function to be minimized 11... 'ndim_problem': ndim_problem, # dimension of cost function 12... 'lower_boundary': -10.0*np.ones((ndim_problem,)), # lower search boundary 13... 'upper_boundary': 10.0*np.ones((ndim_problem,))} # upper search boundary
to utilize the easy-to-use unified (API) interface provided for all BBO in this library, e.g.:
1>>> import numpy as np # engine for numerical computing 2>>> def rosenbrock(x, args): 3... return args*np.sum(np.square(x[1:] - np.square(x[:-1]))) + np.sum(np.square(x[:-1] - 1.0)) 4>>> ndim_problem = 10 5>>> problem = {'fitness_function': rosenbrock, # cost function to be minimized 6... 'ndim_problem': ndim_problem, # dimension of cost function 7... 'lower_boundary': -5.0*np.ones((ndim_problem,)), # lower search boundary 8... 'upper_boundary': 5.0*np.ones((ndim_problem,))} # upper search boundary 9>>> from pypop7.optimizers.es.maes import MAES # replaced by any other BBO in this library 10>>> options = {'fitness_threshold': 1e-10, # to terminate when the best-so-far fitness is lower than 1e-10 11... 'max_function_evaluations': ndim_problem*10000, # maximum of function evaluations 12... 'seed_rng': 0, # seed of random number generation (which should be set for repeatability) 13... 'sigma': 3.0, # initial global step-size of Gaussian search distribution 14... 'verbose': 500} # to print verbose information every 500 generations 15>>> maes = MAES(problem, options) # to initialize the black-box optimizer 16>>> results = maes.optimize(args=100.0) # args as input arguments of fitness function 17>>> print(results['best_so_far_y'], results['n_function_evaluations']) 187.57e-11 15537
When there are multiple (>=2) input arguments except the sampling point x, all of them should be organized (in dict or tuple form) via a function or class wrapper.
For Advanced Usage
Typically, two problem definitions upper_boundary and lower_boundary are enough for most end-users to control the initial search range. However, sometimes for benchmarking-of-optimizers purpose (e.g., to avoid utilizing symmetry and origin to possibly bias the search), we add two extra definitions to control the initialization of population/individuals:
initial_upper_boundary: upper boundary only for initialization (array_like),
initial_lower_boundary: lower boundary only for initialization (array_like).
If not explicitly given, initial_upper_boundary and initial_lower_boundary are set to upper_boundary and lower_boundary, respectively. When initial_upper_boundary and initial_lower_boundary are explicitly given, the initialization of population/individuals will be sampled from [initial_lower_boundary, initial_upper_boundary] rather than [lower_boundary, upper_boundary].
Optimizer Setting
This library provides a unified API for hyper-parameter settings of all BBO. The following algorithm options (all stored into the dict format) are very common for all BBO:
max_function_evaluations: maximum of function evaluations (int, default: np.inf),
max_runtime: maximal runtime to be allowed (float, default: np.inf),
seed_rng: seed for random number generation (TNG) needed to be explicitly set (int).
At least one of two algorithm options (max_function_evaluations and max_runtime) should be set according to the available computing resources or acceptable runtime (i.e., problem-dependent). For repeatability, seed_rng should be explicitly set for random number generation (RNG). Note that as different NumPy versions may use different RNG implementations, repeatability is guaranteed mainly within the same NumPy version.
Note that for any optimizer, its specific options/settings (see its API documentation for details) can be naturally added into the dict data structure. Take the well-known Cross-Entropy Method (CEM) as an illustrative example. The settings of mean and std of its Gaussian sampling distribution usually have a significant impact on the convergence rate (see its API for more details about its hyper-parameters):
1>>> import numpy as np 2>>> from pypop7.benchmarks.base_functions import rosenbrock # function to be minimized 3>>> from pypop7.optimizers.cem.scem import SCEM 4>>> problem = {'fitness_function': rosenbrock, # define problem arguments 5... 'ndim_problem': 10, 6... 'lower_boundary': -5.0*np.ones((10,)), 7... 'upper_boundary': 5.0*np.ones((10,))} 8>>> options = {'max_function_evaluations': 1000000, # set optimizer options 9... 'seed_rng': 2022, 10... 'mean': 4.0*np.ones((10,)), # initial mean of Gaussian search distribution 11... 'sigma': 3.0} # initial std (aka global step-size) of Gaussian search distribution 12>>> scem = SCEM(problem, options) # initialize the optimizer class 13>>> results = scem.optimize() # run the optimization process 14>>> # return the number of function evaluations and best-so-far fitness 15>>> print(f"SCEM: {results['n_function_evaluations']}, {results['best_so_far_y']}") 16SCEM: 1000000, 10.328016143160333
Please refer to e.g., the following books or papers as some of representative references to Hyper-Parameter Optimization (HPO):
Hutter, et al., 2019. [Automated machine learning: Methods, systems, challenges](https://www.automl.org/wp-content/uploads/2019/05/AutoML_Book.pdf). Springer.
Bergstra and Bengio, 2012. [Random search for hyper-parameter optimization](https://www.jmlr.org/papers/v13/bergstra12a.html). JMLR, 3(10), pp.281-305.
Hoos, 2011. [Automated algorithm configuration and parameter tuning](https://link.springer.com/chapter/10.1007/978-3-642-21434-9_3). In Autonomous Search (pp. 37-71). Springer.
Result Analysis
After the ending of optimization stage, all black-box optimizers return at least the following common results (collected into a dict data structure) in a unified way:
best_so_far_x: the best-so-far solution found during optimization,
best_so_far_y: the best-so-far fitness (aka objective value) found during optimization,
n_function_evaluations: the total number of function evaluations used during optimization (which never exceeds max_function_evaluations),
runtime: the total runtime used during the entire optimization stage (which does not exceed max_runtime),
termination_signal: the termination signal from three common candidates (MAX_FUNCTION_EVALUATIONS, MAX_RUNTIME, and FITNESS_THRESHOLD),
time_function_evaluations: the total runtime spent only in function evaluations,
fitness: a list of fitness (aka objective value) generated during the entire optimization stage.
When the optimizer option saving_fitness is set to False, fitness will be None. When the optimizer option saving_fitness is set to an integer n (> 0), fitness will be a list of fitness generated every n function evaluations. Note that both the first and last fitness are always saved as the beginning and ending of optimization. In practice, setting saving_fitness properly could generate a low-memory data storage for final optimization results.
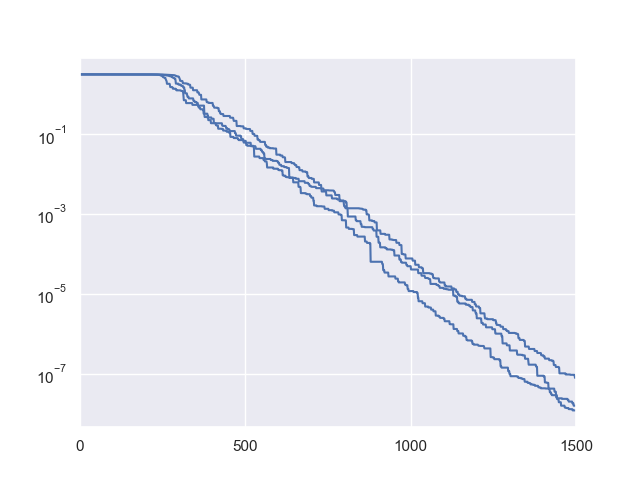
Below is a simple example to visualize the fitness convergence procedure of Rechenberg’s (1+1)-Evolution Strategy on the classical sphere function (one of the simplest test functions):
1>>> import numpy as np # https://link.springer.com/chapter/10.1007%2F978-3-662-43505-2_44 2>>> import seaborn as sns 3>>> import matplotlib.pyplot as plt 4>>> from pypop7.benchmarks.base_functions import sphere 5>>> from pypop7.optimizers.es.res import RES 6>>> sns.set_theme(style='darkgrid') 7>>> plt.figure() 8>>> for i in range(3): 9>>> problem = {'fitness_function': sphere, 10... 'ndim_problem': 10} 11... options = {'max_function_evaluations': 1500, 12... 'seed_rng': i, 13... 'saving_fitness': 1, 14... 'x': np.ones((10,)), 15... 'sigma': 1e-9, 16... 'lr_sigma': 1.0/(1.0 + 10.0/3.0), 17... 'is_restart': False} 18... res = RES(problem, options) 19... fitness = res.optimize()['fitness'] 20... plt.plot(fitness[:, 0], np.sqrt(fitness[:, 1]), 'b') # sqrt for distance 21... plt.xticks([0, 500, 1000, 1500]) 22... plt.xlim([0, 1500]) 23... plt.yticks([1e-9, 1e-6, 1e-3, 1e0]) 24... plt.yscale('log') 25>>> plt.show()
For Advanced Usage
Following the recent suggestion from one end-user, we add EARLY_STOPPING as the fourth termination signal. Please refer to #issues/175 for details.
Algorithm Selection and Configuration
For most real-world black-box optimization, typically there is few a prior knowledge to serve as the base of algorithm selection. Perhaps the simplest way to algorithm selection is trial-and-error. However, here we still hope to provide a rule of thumb to guide algorithm selection according to algorithm classification. Refer to our GitHub homepage for details about three different classification families (only based on the dimensionality). It is worthwhile noting that this classification is just a very rough estimation for algorithm selection. In practice, the algorithm selection should depend mainly on the performance criteria to be focused (e.g., convergence rate and final solution quality) and maximal runtime to be available.
In the future, we expect to add the Automated Algorithm Selection and Configuration techniques into this open-source Python library, as shown below (just to name a few):
Lindauer, M., Eggensperger, K., Feurer, M., Biedenkapp, A., Deng, D., Benjamins, C., Ruhkopf, T., Sass, R. and Hutter, F., 2022. SMAC3: A versatile Bayesian optimization package for hyperparameter optimization. JMLR, 23(54), pp.1-9.
Schede, E., Brandt, J., Tornede, A., Wever, M., Bengs, V., Hüllermeier, E. and Tierney, K., 2022. A survey of methods for automated algorithm configuration. JAIR, 75, pp.425-487.
Kerschke, P., Hoos, H.H., Neumann, F. and Trautmann, H., 2019. Automated algorithm selection: Survey and perspectives. ECJ, 27(1), pp.3-45.
Probst, P., Boulesteix, A.L. and Bischl, B., 2019. Tunability: Importance of hyperparameters of machine learning algorithms. JMLR, 20(1), pp.1934-1965.
Hoos, H.H., Neumann, F. and Trautmann, H., 2017. Automated algorithm selection and configuration (Dagstuhl Seminar 16412). Dagstuhl Reports, 6(10), pp.33-74.
Rice, J.R., 1976. The algorithm selection problem. In Advances in Computers (Vol. 15, pp. 65-118). Elsevier.